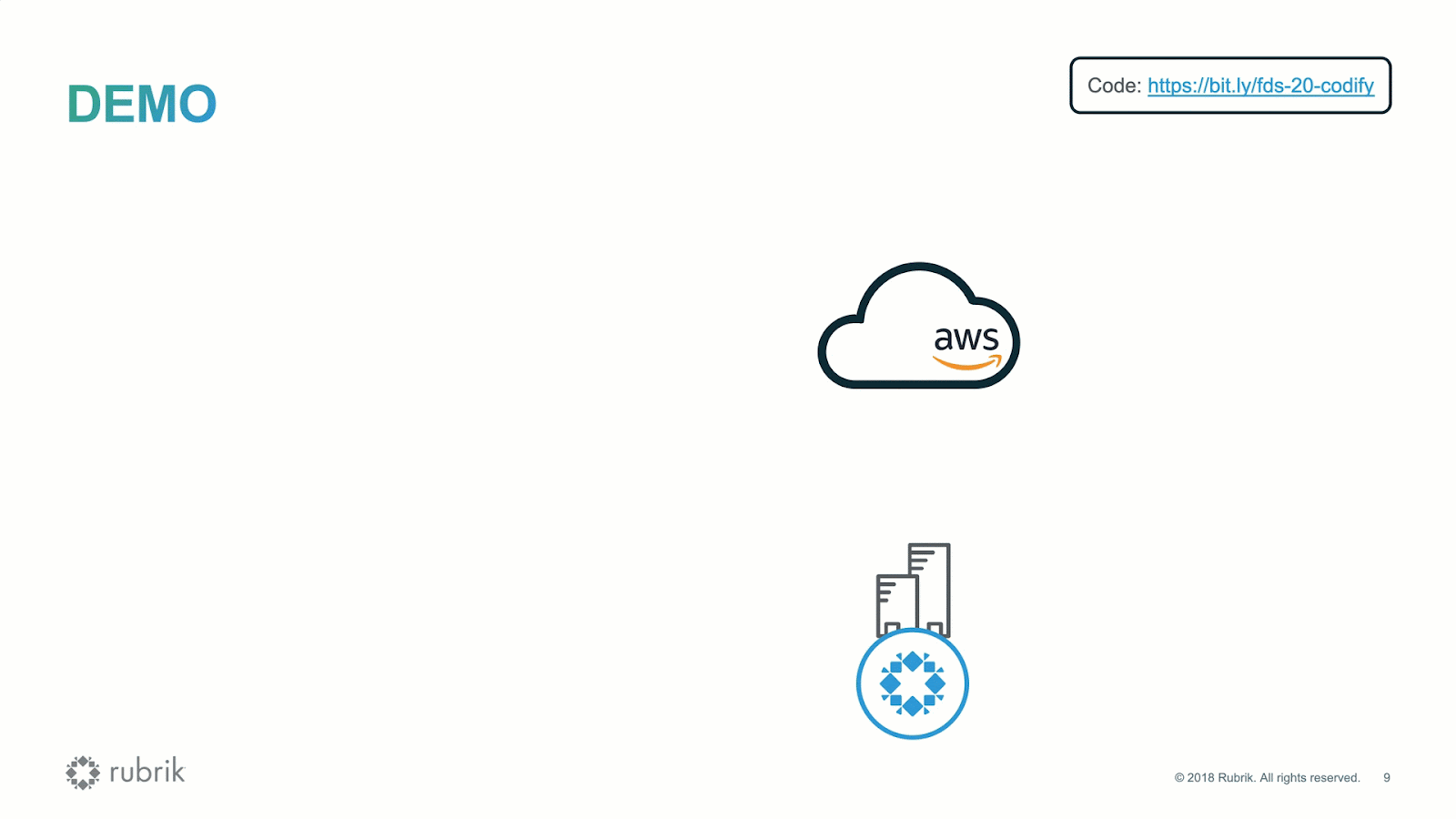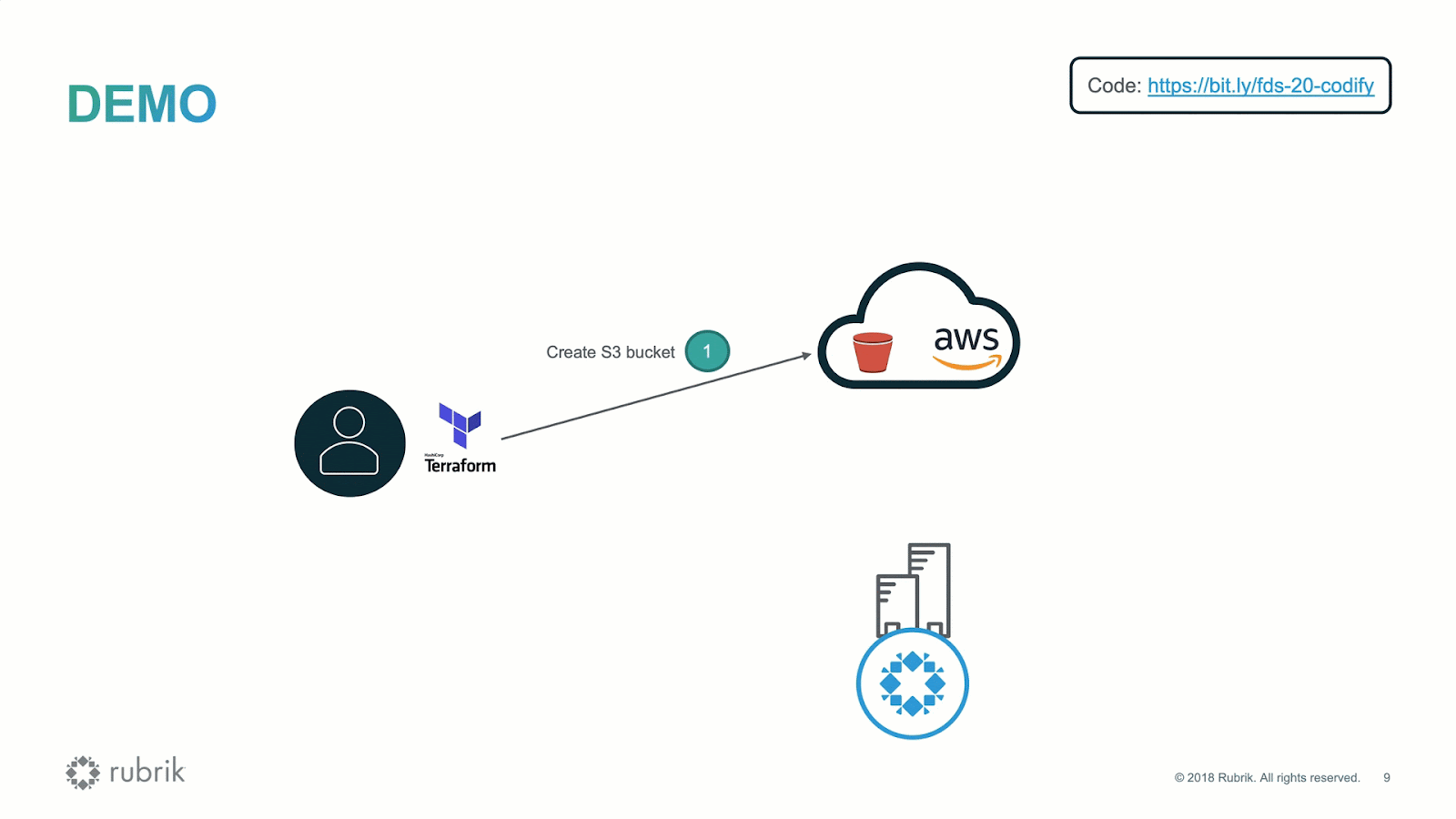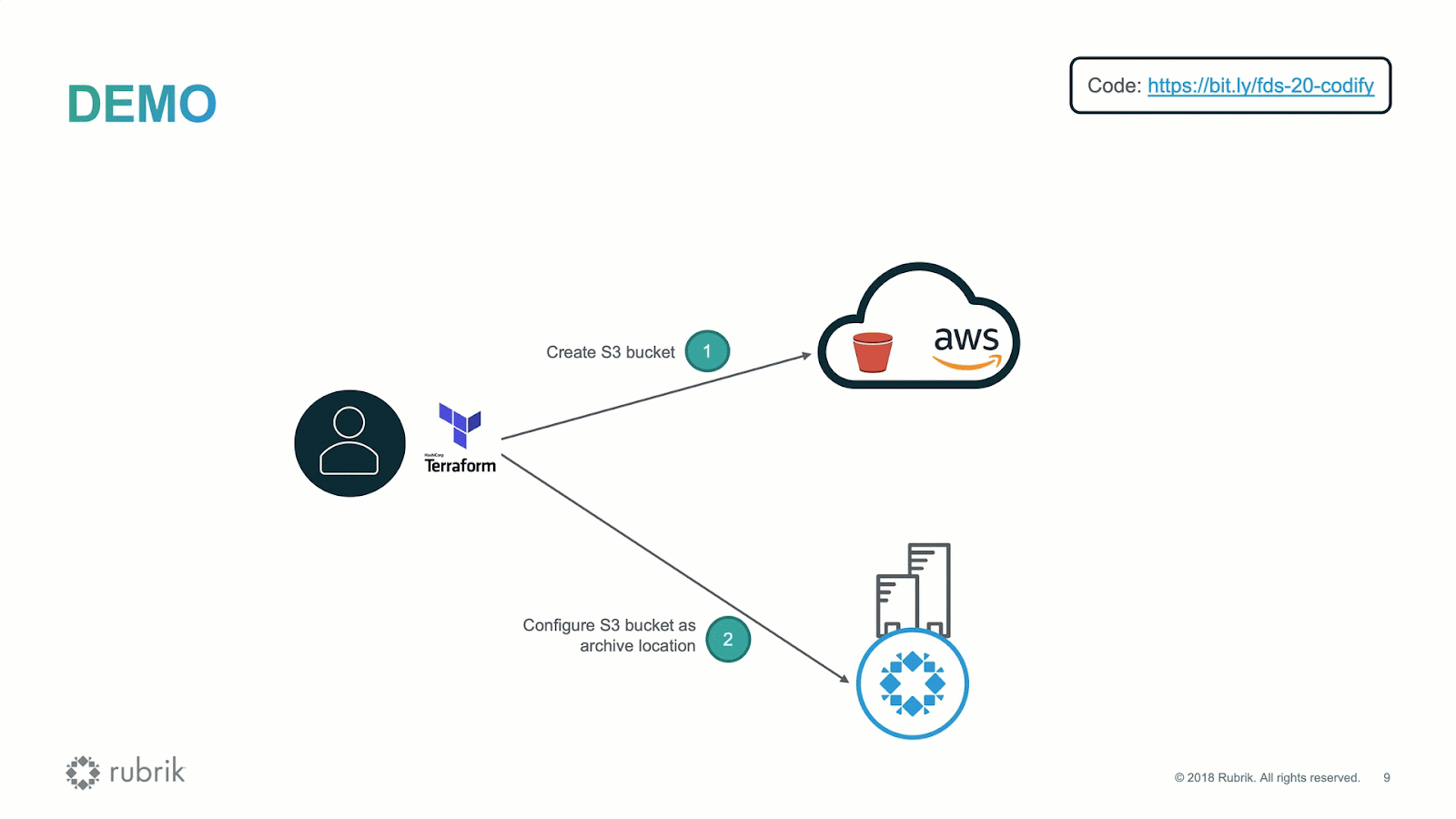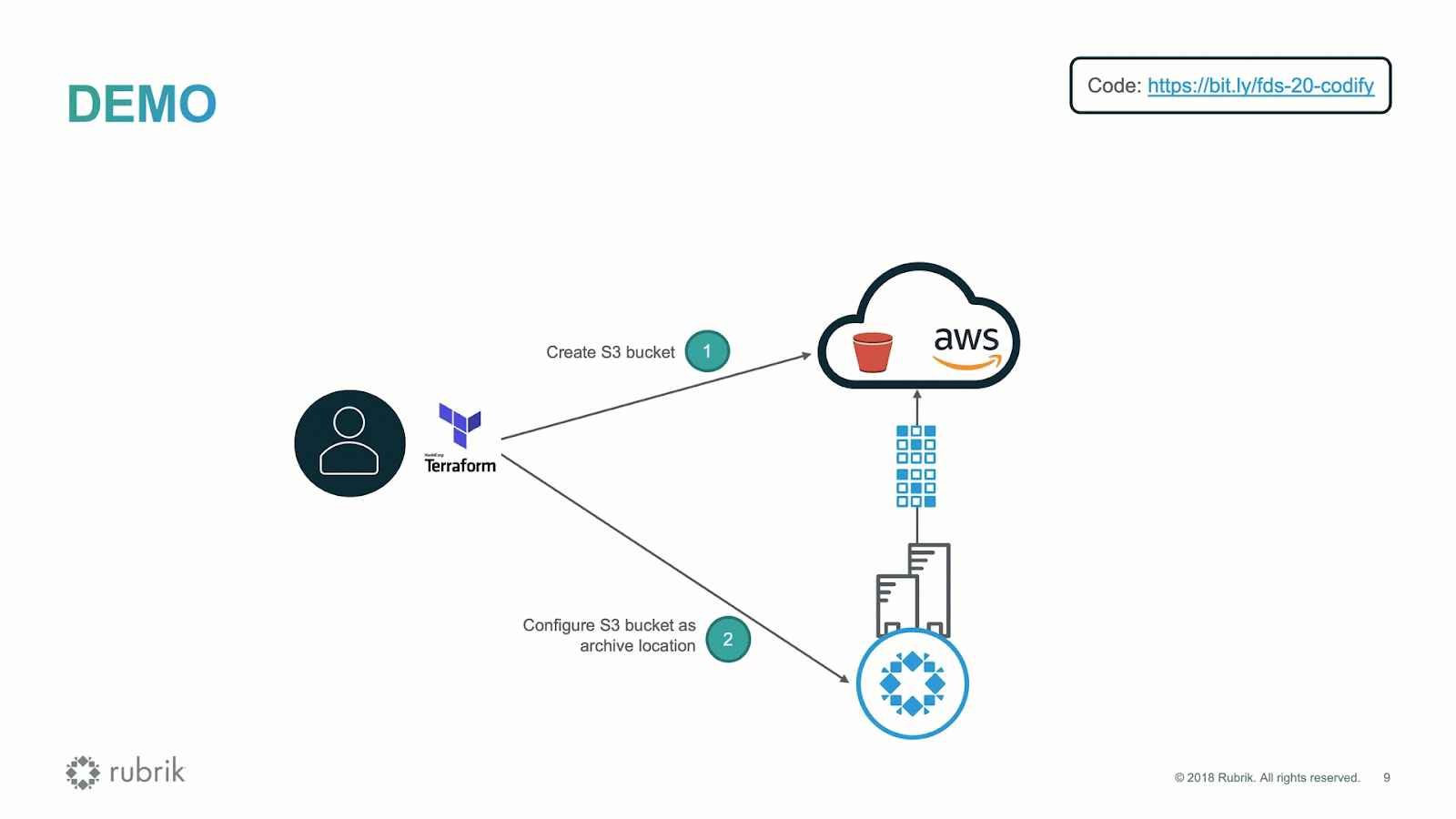
Every technology-focused business needs the right technical and architectural experience to make technical decisions effectively, balancing the trade-offs.
Decision-making is the cognitive process of selecting a course of action among several possible alternative options. Technical decision-making is less about the tool to pick and more about the problem to solve. Once the problem space is well defined, then evaluating the possible solutions becomes a lot easier. Technical decision-making cannot be outsourced.
Engineering organizations of all sizes make technical decisions every day. Every person in a technical role makes decisions, though the scope may vary across roles. Most of the time, these decisions are on a relatively small scale: an individual engineer or a small team solving a problem in the way that makes the most sense to them.

There is proportionality to each decision. Some decisions have a much broader impact, and it’s essential to have a process for capturing those decisions. Such decisions contribute to a deeper vision of how your stack or toolchain is evolving in response to changing technology and business landscape.
Scope the problem
First, what are you deciding (and why)? Determining the actual decision and scope is the first step toward having a rational plan to execute once the decision is made. Think about how you can frame the decision as a concrete question.
Failing to do this results in people discussing from different premises, causing misalignment about what the decision or project actually entails. When exploring the problem area, consider the following:
- Specificity – an actionable problem statement takes aim at a particular issue. Avoid boiling the ocean.
- Decision-maker criteria – defines what information is needed by the decision-maker(s) to select a path forward.
- Contextual constraints – this is the landscape the decision is made in; for example, capabilities of existing infrastructure, the business landscape, and laws of physics.
- Timeframe and level of accuracy required – for example, a go/no-go decision must be made by the end of the quarter, or the projected cost savings must be accurate +/- 20%.
- Plan of action – clearly understands what outcomes are achievable once this problem is solved and communicates the immediate next step.
A problem that is well understood is already half-solved and generally leads to better solutions. Avoid defining any solution at this stage.
“If I had an hour to solve a problem, I’d spend 55 minutes thinking about the problem and 5 minutes thinking about solutions.” ― Albert Einstein
Avoid scope creep
The impact of scope creep is almost always negative because the work increases, but the timeframe does not. Scope creep is notorious for taking focus away from the actual problem and blowing out timelines. Increasing the problem’s scope will only result in choosing an over-engineered solution or solving challenges you don’t currently have.
There are commonly three adjustable levers: scope (i.e., what is included as part of a problem to be solved, or what factors to consider in a decision), resourcing (i.e., availability and quantity of personnel that can work as a team on the problem), and timing (i.e., when the work needs to be delivered, or by when the decision must be made). Often, the scope is increased without adjusting the other two levers – inevitably causing problems.
Ensuring that scope additions are relevant to the problem being addressed is crucial. If the scope increases, then reevaluate the resourcing and timing for the decision or project.
Prioritization
Prioritizing which problem to solve is a particularly challenging part of decision-making. There’s usually a laundry list of problems to solve or things to do at any given time. The Eisenhower Matrix is an effective way to help organize tasks by urgency and importance.

In more detail, the quadrants are:
- Do it now – a task or decision that requires immediate attention. When something is urgent, it must be done now, and there are clear consequences if the decision is not made within a specific timeline.
- Schedule it – may not require immediate attention, but these tasks or decisions help achieve long-term goals. Just because these tasks are less urgent doesn’t mean they don’t matter – instead, they need to be thoughtfully planned to ensure resources are efficiently used.
- Delegate it – tasks or decisions that are urgent but not important. These tasks must be completed sooner but don’t affect long-term goals. Because there is no personal attachment to these tasks or decisions and they don’t require a specific skill set, these can be delegated to other team members.
- Don’t do it – these are unimportant, non-urgent distractions that get in the way of accomplishing goals.
Be wary of the “tip of the iceberg” approach. It’s easy to solve the most visible problem, but often the real issue lurks beneath the surface. Identifying the real problems requires having a deep understanding of the system (and other systems it interacts with). However, there may be limits to what one can know or what data one can collect.
Data-driven decision-making works best when buttressed with good intuition and instincts, particularly when making decisions while missing bits of critical data. I learned the 75% method while in the Marine Corps, which prescribes collecting information until you have about 75% of the data needed. Then use your expertise, experience, and gut to fill out the other 25%.
Weigh the factors
Making the right decisions, especially ones that have a broad impact, can be challenging. It’s never as simple as writing down a list of pros and cons. Numerous aspects and their varying importance have to be considered. This evaluation begins by defining the decision criterion.
Decision criteria are principles, factors, or requirements used to make a decision. This criterion can be as rigid as detailed specifications and criteria scoring; or as flexible as a rule of thumb. Some examples include monetary cost, opportunity cost, ROI, risk, strategic fit, and sustainability.
Some decision criteria are discrete; others are continuous. It’s possible to devise a scorecard-like approach or weighted matrix against which to measure each option. Remember that some criteria may be more subjective, so this is an imperfect science. However, a clear view of the criteria can demonstrate how a range of decision options compare.
Manage risk
Effective decision-making is about using the best judgment. Best judgment means having an opinion, going out on a limb, leveraging experience, and taking risks. Part of the decision-making process is managing those risks and minimizing the risk factors.
Intuitively, when considering risk, we focus on the probability of adverse events while neglecting their impact. Risk, however, is the possibility of something terrible happening, compounded by its consequences.
The NASA Risk Management Handbook defines risk as the following elements:

- Scenario – a sequence of credible events that specify the evolution of a system from a given state to an undesired condition.
- Likelihood – the measure of how possible the scenario is to occur; it can be qualitative or quantitative.
- Consequences – the impact should any of the scenarios occur; the severity can be qualitative (e.g., reputational damage) or quantitative (e.g., money lost).
Consider the reversibility of the decision. One-way door decisions are decisions that you cannot easily reverse. These decisions need to be made carefully. Two-way door decisions can be reversed. You can walk through the door, see if you like it, and if not, go back. These decisions can be made fast or even automated.
When making a critical, one-way door decision, try to reduce risk by transforming it into a two-way door decision or reducing exposure. Keep in mind that this changes the risk profile but does not change the importance or urgency of the decision.
Declare dependencies
Decisions don’t live in isolation. Decisions are constrained by and depend on the context in which they are being made. Managing dependencies is an integral part of decision-making and executing the decision once made. Unknown dependencies introduce more risk to a decision.
There are several types of dependencies to be aware of:
- Technical dependency – the relationship between two decisions that affect the technical outcome of a decision.
- Schedule dependency – the relationship between two decisions where the timing of one impacts the other.
- Resource dependency – a shared critical resource between two decisions.
- Information dependency – a relationship where information shared between decisions would impact the scope or consequence of a decision.
The directional relationship of these dependencies may be upstream or downstream.
Upstream dependencies are things that a decision is reliant on happening before the decision can be made. These things need to happen upstream and flow down into the decision.
If upstream dependencies have to happen before a decision can be made, downstream dependencies occur afterward. Any delay in making the decision will impact the downstream dependency.
Make the decision
There is the possibility of making a bad decision. Because decisions can only be evaluated after the fact, it can be costly to revert a decision because it’s often already embedded into systems and processes. So what does a good decision look like?
- It’s a decision. Deciding not to decide is still a decision. But not deciding is a non-decision.
- The problem and desired outcome are clearly stated.
- Context is considered. This may include the business or economic environment, team constraints, and other factors.
- The decision is informed by feedback from people with different perspectives.
- Trade-offs are weighed, as well as how to manage them.
- It considers what could go wrong, and risks are documented.
- Assumptions are stated as well as a way to validate them.
There is no perfect decision without trade-offs, and it’s possible to go back and forth about a decision forever. Make the final call and provide clarity to anyone affected by the decision. At this point, the decision maker should be clear about what is being done and the next steps. Teams must be aligned on why this direction is important, the desired outcome, and how this aligns with our strategy and vision.
Foster discussion and gather feedback
Decisions do not occur in a vacuum. The decision driver should meet consistently with stakeholders and foster discussion. This is where people can ask questions, gain a shared understanding, and reach buy-in. There may be multiple rounds of discussions during the decision-making process. It may begin with a conversation about the problem area, and more specific meetings occur later on particular topics.
It’s easy to say, “I’m open to feedback,” but creating space for feedback is vital. It can be helpful to frame the question to gather specific feedback (e.g., “is there any context missing?”). Making space for feedback can include:
- Space out the different constructs of the decision (e.g., just the scope of the problem for one conversation, then discuss trade-offs the next) to give stakeholders time to digest, ask questions, form opinions, and comment.
- Facilitate discussion to hear from a broad range of opinions, including those who dissent and others who are less inclined to share.
- Make people comfortable to share feedback with the group, but also work behind the scenes to collect feedback 1:1 that they may not want to share publicly.
Feedback is often captured in the form of trade-offs (i.e., what we give up to invest in a particular option). This demonstrates that the feedback was heard and weighed, but other factors are being prioritized.
There is the possibility of making a bad decision. It is costly to revert a decision already embedded into systems and processes. Thus, gathering feedback early and often helps identify issues or overlaps sooner and allows you to gain acceptance of your technical decision.
Document the decision
By now, the data has been collected, a clear problem is being solved, and the hypothesis on the correct direction and a way to measure the outcome have been defined. Feedback has been heard and incorporated into the decision. Now the decision must be documented. Similar to feedback, this is something that should be happening throughout the process.
The purpose of documenting a decision is to capture all the contextual information in one place. The act of writing solidifies the decision, solicits broader feedback, and allows for widespread communication. Documenting the decision also helps in other ways, such as:
- Alignment – teams need to understand the historical landscape and context of the decision; a decision’s impact may outlast the decision maker’s tenure.
- Reduce duplicate effort – avoid wasting time and effort by repeating past discussions.
- Retrospective – context may change; understand why the decision was made at that time and why it was the right/wrong decision.
It is helpful to have a decision-making model, such as DACI, RACI, or ADR. No matter which you choose, it should clearly capture the decision, trade-offs, and the roles and responsibilities of those involved.
Communicate the decision
Once the decision is made, socialize it with the stakeholders. A common anti-pattern is reaching a decision and not sharing this; eventually, it causes distrust and disharmony in those affected by the decision. Instead, bring them on the journey and make them feel part of the decision-making process.
Ultimately, create a document of the decision to ensure future members understand its rationale. Share widely in the correct communication channels and then focus on aligning people with the next steps and why a decision has been made.
Useful Frameworks
This section provides a few different frameworks that can be adapted for driving important decisions. Frameworks are like shoes; some will fit more comfortably than others. If a framework doesn’t feel natural to you, then either find one that does or adapt the framework into terms that work for you.
SPADE
Created by Gokul Rajaram while working at Google, the SPADE framework is intended to help build the decision-making muscle to enable faster decision-making. The framework is a quick assessment of the problem and the decision being made and then used to bring others up to speed. The elements are:
- Setting – contextualizes the decision by defining the “what” and parsing the objective to explain the “why.”
- People – defines the roles and responsibilities of those involved in the decision-making process.
- Alternatives – outline the realistic options available, the impact of each choice, and its evaluation against the decision’s setting.
- Decide – weigh the information, consider people’s feedback, and then make the decision; choose an alternative and detail why it was chosen.
- Explain – articulate why the alternative was selected, the impact of the decision, and any associated risks; communicate with stakeholders.
The decision-making framework outlines a step-by-step process to synchronize and speed up collaborative decisions.
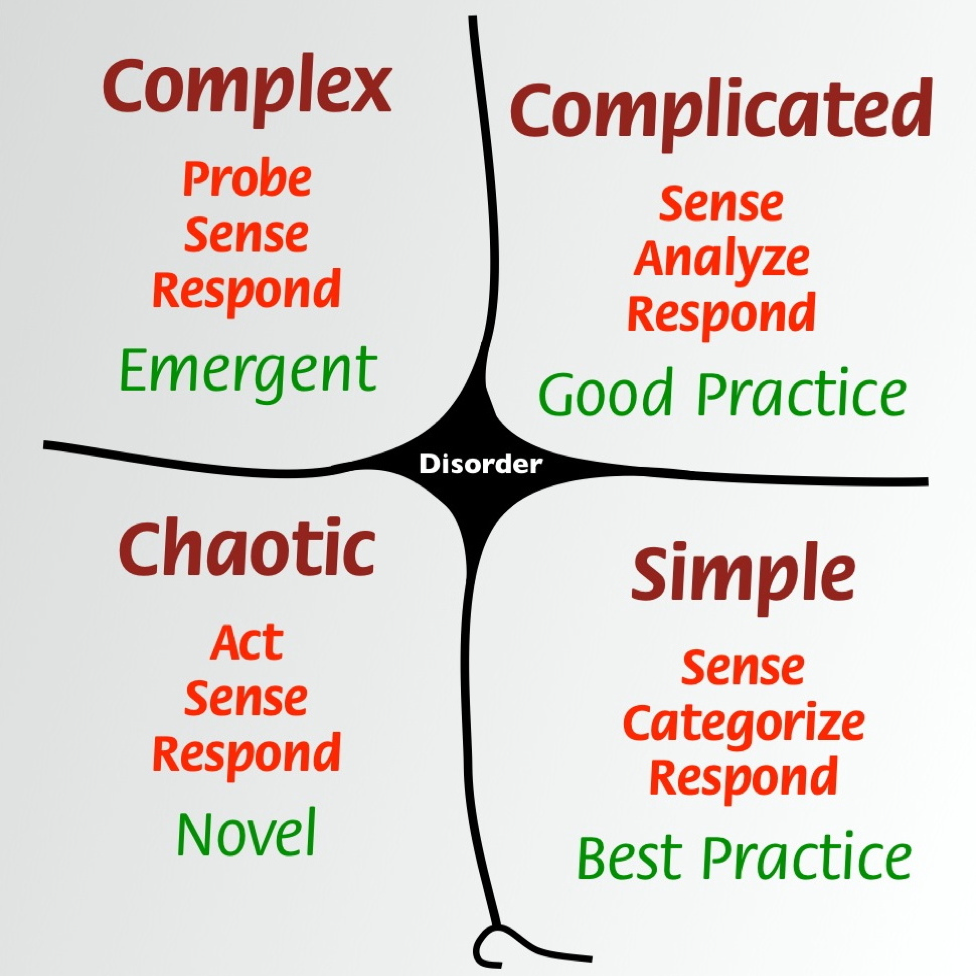
Cynefin
The Cynefin Framework gives context to decision-making by providing context and guiding a response. It is a sensemaking framework to help think through the details of a situation, classify it, and understand the appropriate response to the situation. The five domains of the Cynefin Framework are:
- Obvious – the relationship between cause and effect is already well-known; respond according to established practices.
- Complicated – the relationship between cause and effect is knowable; the situation can be analyzed to form a hypothesis of what should be done.
- Complex – the relationship between cause and effect is unknowable; experiments or spikes should be conducted to understand the situation.
- Chaotic – the situation is very unstable; one must act quickly, and there is no time to conduct experiments or analyze the situation.
- Disorder – not determined; anything whose domain has not been identified falls into this domain.
These domains help decision-makers create an awareness of what is really complex and what is not. From there, the decision maker can respond accordingly so that no energy is wasted in overthinking the problem and to ensure that they aren’t trying to make the complex fit into standard solutions or vice versa.
OODA
The Boyd Cycle, also known as “the OODA Loop,” is a concept used to describe a recurring decision-making cycle. The goal is to process the cycle quickly and continuously, allowing the decision-maker to react quickly to the changing environment. The four elements are:
- Observe – continued awareness of the situation, context, and any changes. The first step is to identify the problem and gain an overall understanding of the environment.
- Orient – reflect upon what was observed, and consider what should be done next. This step recognizes, diagnoses, and analyzes the observed situation.
- Decide – suggest a course of action, considering the trade-offs and acceptable degree of risk.
- Act – turn the decision into action, and measure the outcome.
Once a decision is made, the situation changes. Thus, the OODA Loop turns on itself and repeats again and again.
Conclusion
Balancing the past, present, and future is challenging when making a technical decision. This process requires patience, understanding, and problem-solving. Technical leaders are stewards of this process and should focus on the outcomes of a decision (rather than implementation or execution details) and aligning teams around why a decision was made.
Technical decision-making is complex; even the best decisions sometimes don’t turn out as you’d hoped. You can improve your decision-making skills by revisiting old decisions. Was there a missed context? Trade-offs that turned out to be different than expected? A good decision-making process can help confidently deliver technical decisions consistent with long-term strategy and architectural principles.