Effective leaders know that problem solving is not “one-size-fits-all”. The action taken depends on the situation and, because the circumstances are changing, better decisions can be by using an adaptive approach. I have previously written about the 75% method that I learned in the military, but there’s another framework that I have consistently used with success.
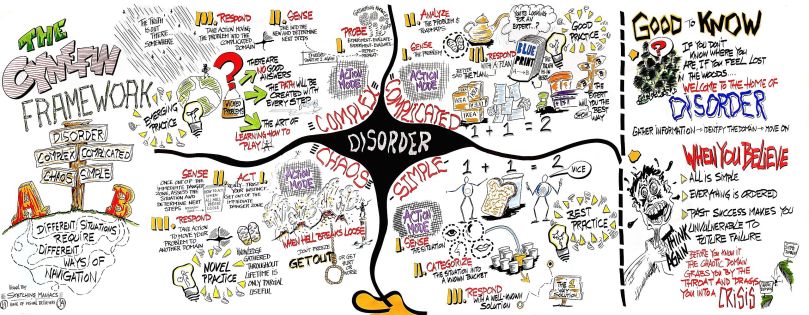
Cynefin, pronounced “kih-neh-vihn” (don’t worry, I mispronounced it for longer than I’d like to admit), is a Welsh word that means “place”. The Cynefin framework was coined in 1999 by Dave Snowden. Simply, the Cynefin framework is used to help realize that not all situations are equal and to successfully navigate different situations, different responses are required.

The 5 Domains
Problems are categorized into five domains using the Cynefin framework (yes, five, don’t forget disorder!).
Ordered Systems
The domains on the right (obvious and complicated) are “ordered” because cause-and-effect are known or can be discovered.
Obvious (fka “Simple”)
This is the domain of best practice.
In this context, the problems are apparent cause-and-effect relationships that are well understood.
The methodology is to “sense – categorize – respond” to obvious problems. This means that the situation should be assessed, categorized by type, and then respond based on an existing process or procedure. These tend to be repeating patterns and/or consistent events…or “known knowns”.
For example, these are problems faced at a helpdesk or call center – often predictable and there are established processes in place to handle the vast majority.
Be careful – some obvious contexts may be oversimplified. This happens when leaders (or organizations, for that matter) experience success and become complacent as a result. Ensure that there are feedback loops in place so that any situations that don’t exactly fit with an established category can be reported.
Another risk with complacency is that leaders may not be receptive to new ideas. Endeavor to stay willing to pursue a new or innovative suggestion.
Complicated
This is the domain of good practice. Sometimes referred to as the “domain of experts.”
Complicated problems may have multiple correct solutions. There is a relationship between cause and effect, but it may not be obvious to everyone because the problem is…well…complicated. There may be several symptoms but you are not sure how to fix them.
The methodology here is to “sense – analyze – respond”. Effectively you should assess the situation, analyze what is known (using the help of experts), and decide what the best response is using good practices. This is generally where we experience “known unknowns” where we know the questions that need to be answered, but may not know the actual answer. It is at this point that we consult the expert. With enough time, you could reasonably identify the known risk and develop a plan. Think evolutionary, not revolutionary.
The danger here is that a leader may lean too heavily on experts while ignoring good solutions from others. In tech, we tend to experience this where we rely on the experts and ignore the generalists – even though the generalist may have the winning answer. Additionally, the leader may experience analysis paralysis. This is where I recommend using the 75% method detailed here.
Unordered Systems
The domains on the left (complex and chaotic) are “unordered” because cause and effect can be deduced only with hindsight or potentially not at all.
Complex
This is the domain of emergent practice.
Sometimes it is impossible to identify a single correct solution or to spot the cause-and-effect relationship. You are likely in a complex context.
This context is typically unpredictable, making the best approach “probe – sense – respond”. Think “unknown unknowns”. You may not know the correct questions to be asking. Regardless of how much time is spent in analysis, it may not possible to accurately identify the risks, predict the solution, or the effort needed to solve the problem.
In this situation, it is best to patiently wait, look for patterns, develop, and experiment to gain more knowledge. As more knowledge is gained, then determine the next steps. Repeat as needed. The goal is to move into the “complicated” domain.
A potential risk is that leaders may fall back into habitual command-and-control modes which are futile in this context. Leaders lacking patience may try to force facts instead of waiting for patterns. It is imperative to have a feedback loop so that open discussion can occur to develop experiments for observing patterns. Think “what if we tried…” Use creativity to solve the problem.
Complicated and complex situations are similar in some ways, and are sometimes confused. If a decision based on incomplete data is being made, you are likely to be in a complex situation.
Chaotic
This is the domain of novel practice.
There is no relationship between cause-and-effect. This means that the primary goal here is to establish order and stability. This is likely a crisis or emergency situation.
The methodology is to “act – sense – respond”. It is necessary to be decisive in order to address the burning issues, determine where there is and isn’t stability, and then work to move the situation from chaos to complexity. Basically, shit has hit the fan – triage time: stop the bleeding and start the breathing… then determine what the real solution should be.
It may feel like in tech we live in this domain (hopefully not!). As an example, there may be an issue in production, say a bad patch that has been installed data center wide. Initially the focus will be on containing the issue and correcting it quickly. The initial solution may not be great, but it gets the job done. Once the bleeding has stopped then you can determine the better long-term solution.
In this situation, the leader must provide clear and direct communication while taking immediate action to re-establish order. A risk is an indecisive leader. This is the time to find “good enough” instead of the perfect answer.
Disorder
Disorder is the space in the middle.
There is no clarity here – decompose and move to another context. Basically, if you have no idea where you are, then you’re likely in “disorder”. The immediate goal is gather information in order to move to a known domain.
In this situation, I tend to try to break the massive disorder into smaller problems and then tackle each one individually. Apply each problem to a domain and work on a solution.
Chaotic problems are dangers, especially when left unaddressed, because there is no process to fix it. This is why it is important to move into a known category.
Final Thoughts
The Cynefin Framework is an excellent model to assist in approaching different situations. Once the situation is defined, then work to solve the problem.
The goal is to adequately lead your team through any of these five domains. Many leaders can only lead effectively in one or two domains (not in all of them) and few, if any, prepare their organizations for diverse contexts. The only way to successfully get through all five domains is to keep an open mind to new and creative solutions, build a feedback loop, and not get stuck in analysis paralysis.
Additional Resources:
Cognitive Edge: The Cynefin Framework (explained by Snowden himself!)
Everyday Kanban: Understanding the Cynefin framework – a basic intro
Sherrieg: The Cynefin Framework
Harvard Business Review: A Leader’s Framework for Decision Making






